
Hyde & Rugg:
We solve hard problems
Hyde & Rugg:
We solve hard problems
Overview
This topic is at the heart of our Verifier approach, which is the subject of Gordon’s book Blind Spot.
An obvious approach to error detection is to use formal logics, but in practice this doesn’t work well.
At a practical level, formal logics usually run into problems with real world problems, because of the messy, uncertain, incomplete nature of real world knowledge.
At a theoretical level, formal logics don’t address some important aspects of human error. For example, one common cause of errors and accidents is ‘strong but wrong’ errors. These involve someone doing the usual thing instead of the correct thing. There’s a substantial body of work on human error, but it’s very different in its nature from formal logics, and it hasn’t been well integrated with more formal approaches.
Within our work, we’ve focused on two main issues relating to the problems described above.
We’ve worked on ‘upstream’ issues of eliciting and representing knowledge in a form that is suitable for formal analysis, but that is also reasonably accurate, complete and valid.
We’ve also worked on ways of integrating various approaches to error detection within a framework that’s systematic and solidly grounded in both practical and theoretical terms.
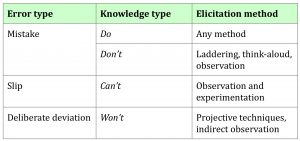
As an example of our approach, the table below shows how different types of error can be mapped onto appropriate elicitation methods for investigating each error type.
Topics
We’ve taken it for granted that formal logics are an important part of error detection. In practice, though, we’ve seldom had to rely on them, because we usually detect significant errors before we reach the stage of using formal logics.
Formal logics depend on explicit, step-by-step serial processing, which is slow, and typically involves reformatting knowledge into a suitable input format.
For our initial analysis of problems, we usually use parallel processing and pattern matching, which are much faster.
In this stage, we draw heavily on a range of work in the J/DM (Judgment/Decision Making) tradition, including Kahneman and Gigerenzer, to identify common errors and biases. We’re aware of the apparently contradictory findings of the heuristics and biases school and of the frequentist approaches; we adopt a pragmatic approach to this in our first pass analyses.
We also make routine use of set theory, particularly the use of crisp sets and fuzzy sets, as a way of clarifying assertions in the literature that we’re assessing.
We’ve found systematic visual representation invaluable in error detection.