
Hyde & Rugg:
We solve hard problems
Hyde & Rugg:
We solve hard problems
COMPUTERS vs BRAINS: SERIAL AND PARALLEL
PROCESSING
Computers
Computers are good at handling information, as opposed to knowledge. They do this in several principal ways.
One way involves calculation, in the familiar sense of mathematical operations such as add, subtract, divide and multiply. Computers can do this swiftly and efficiently.
Another involves character manipulation. The characters may be alphabetic, such as the letters a, B or X, or may take other forms, such as the dollar character $. Manipulation may involve adding, removing or changing a given character; for instance, replacing the dollar character $ with the characters USD. Manipulation may also involve identifying where a given set of characters occurs within a larger set of characters, such as identifying where the dollar character occurs in a string of text stored in the computer.
A third way involves performing logical operations. A typical example is
IF client age is less than 18
AND client online purchase type = alcohol
OR client purchase type = knife
THEN decline transaction.
In this example, client age is a number, and alcohol and knife are characters. The operation handling the check on the client age is a calculation, and the operations handling the check on purchase type are character manipulation – checking whether the characters for purchase type match the characters k,n,i,f and e immediately adjacent to each other, and ditto for the characters a,l,c,o,h,o and l.
A key point about this example is that the computer is dealing with a string of characters. It has no understanding of what a knife actually is, or what alcohol actually is. It can do huge numbers of logical operations very swiftly and accurately, but it is has no idea what those operations mean in the real world.
Understanding
Understanding the real world requires a very different way of working. Computers usually perform calculations, character manipulation and logical operations in the ways described above, one step at a time. That’s fine for online information handling. It’s nowhere near adequate for real world everyday tasks like identifying that an object in a customer’s checkout basket is a knife as opposed to a pen or a spatula.
One of the big unwelcome surprises for early Artificial Intelligence researchers was that many everyday tasks that humans perform easily are very difficult for computers. A typical example is identifying objects in their environment, such as knowing whether something is an angry dog. With hindsight, this makes complete sense; humans wouldn’t have survived for long if they couldn’t handle those tasks easily. However, handling those essential tasks requires a very different approach from the ones used by computers.
Brains
Serial vs parallel processing
Computers typically use serial processing, which involves doing one thing at a time, in sequence. Human brains, like other animal brains, typically use parallel processing, which involves doing several things simultaneously.
In the example below, the step between A and B is a serial process; so is the step between B and C. However, the steps between C and F involve parallel processing, with one process going via D, and another going via E. The step from F to G is serial.
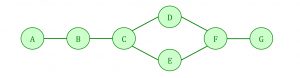
Parallel processing is very good indeed at identifying objects in the environment. In brief, it works like this:
The brain consists of an enormous number of brain cells (neurons), each of which is connected to several other brain cells. The connections form massive networks that process information. And connections between neurons that are used frequently become stronger, in much the same way that a well-used trail over rough ground will become smoother and easier to walk on.
Pattern recognition
Each of the cells in the sense organs is connected to networks of neurons in the brain. The networks connect with each other, which enables us to perceive the big picture of our environment via our sense organs. If patterns in the environment are encountered frequently, connections are strengthened in the networks of neurons activated by those patterns. This results in information being processed more quickly, enabling fast recognition of frequently encountered patterns.
One of the earliest patterns that humans learn is the visual ‘two dots above a horizontal line’ pattern of a human face; one which most babies see repeatedly during their first hours of life. The precise location of the two dots and the line may vary, but the human eye and brain are good at working together to adjust for that.
The patterns can be in any sensory modality, ranging from recognising physical objects, to music and speech, or behaviours. Learning the patterns needed for everyday life takes time; that’s what childhood is about, and that’s why children often make dangerous mistakes if they haven’t seen a particular pattern before.
Pattern recognition is very useful for processing real-world sensory input. And because the real world is messy, the brain needs to be able to handle incomplete, unreliable and incorrect information; parallel processing is great for making decisions such as ‘that animal is probably a friendly dog’ where there’s a degree of uncertainty about whether the animal is a dog rather than, say, a wolf, and about whether the animal is friendly.
However, these strengths come with a price tag. Because the number of patterns the brain needs to recognise is huge, the brain has huge processing capacity for representing patterns. However, the patterns represented are not precise and accurate; they’re about typical values, not exact values. This is a feature, not a bug (in computing terms); it’s a far more efficient process than trying to store the exact figures for every image of a dog that you have ever seen. It does, though, mean that human memory is not a perfect accurate record.